
Introduction
During the process of planning a vacation, I came across a nice hotel I wanted to stay at. When looking at some possible dates, I noticed the nightly rate would fluctuate dramatically. This made me question if I was going to wind up paying way more just because I wanted to stay at the hotel on a certain day.
Then I considered the alternative - maybe I could scrape the prices every day to find the cheapest nightly rate. Sounded like a job for Python, BeautifulSoup, and some whiskey.
A Brief Intro to Python Web Scraping
Web scraping with Python is generally done using a mixture of the fantastic requests and beautifulsoup libraries. This post won’t go into detail about all the neat features of beautifulsoup, instead aiming for simplicity to show the basics.
Getting a BeautifulSoup Object
The first step in web scraping is getting the HTML you want, and creating a parseable object out of it. We can do this by requesting a page with requests.get() and, if successful, creating a BeautifulSoup object using the BeautifulSoup() constructor with the .text of our response.
It would look something like this:
response = requests.get('http://foo.bar')
if response.ok:
soup = BeautifulSoup(response.text)
Getting Data From BeautifulSoup
Now that we have a BeautifulSoup object, we can use its API to get the data we want. The first step is to parse out the Tag object we are interested in. Then, we can parse out the text/attributes we want. Here are some examples of getting specific tags:
soup.find_all('a') # Get all <a> tags
soup.find_all('a', {"class" : "css_class"}) # Get all <a class="css_class"> tags
soup.find_all('a', 'css_class') # Shortcut for searching by class
soup.find() # Same as find_all(), but returns the first instance
After we have the Tag object we want, we can parse out the text by accessing the .text attribute.
This is barely scratching the surface of BeautifulSoup’s API, so if you’re interested in learning more, you can take a look at the docs here. That’s all we’ll need for this post, so let’s see this in action.
Parsing Some (Not Great) HTML
The goal was to simply pull down the rate for each day, and dump it out to a CSV (“rates.csv”) for some sweet Excel graphing later.
I’ll leave the exact hotel and URL redacted, but the basic URL was in the form:
http://foo.bar?month=:int&day=:int&year=:int
We can start with a naive approach of looping through the months I was interested in (August through December) and getting a BeautifulSoup object from each result.
import requests
from bs4 import BeautifulSoup
import time
with open('rates.csv', 'w') as rates:
rates.write("Date,Rate\n")
for m in range(8,13):
for d in range(1,32):
try:
response = requests.get('http://foo.bar?month=' + str(m) + '&day=' + str(d) + '&year=2015')
if response.ok:
soup = BeautifulSoup(response.text)
except Exception e:
print e
# Be (somewhat) nice.
time.sleep(.2)
Now we just need to figure out what kind of data we care about. This site used tables. A lot. After some testing, I wound up parsing HTML that looked like this:
<table summary="rooms availability">
<tbody>
<tr>
<td>
<div class="roomSection">
<div class="roomType">
<span class="value">King</span>
</div>
<div class="roomAvail">
<div class="bar">
<div class="label">Nightly Rate</div>
<div class="value">
159.00 <-- What I want to get
</div>
</div>
</div>
</div>
</td>
</tr>
</tbody>
</table>
I cleaned up the formatting, removed unnecessary parts, etc. Trust me, you’re welcome.
My first step was to get the room type and make sure it was “King” as a sanity check, since there were multiple types of rooms in the table. Then, I wanted to get the text of the div with the class “value” in the “roomAvail” section. This is the nightly rate.
Finally, I want to write the rate out to the CSV file.
There’s definitely more concise ways of doing this with more advanced BeautifulSoup usage, but this code worked:
king = soup.find("table", {"summary" : "rooms availability"}).find("div", "roomSection")
if king.find("div", "roomType").text.strip() == "King":
rate = king.find("div", "roomAvail").find("div", "value").strip()
rates.write("2015-" + str(m) + "-" + str(d) + "," + str(rate) + "\n")
Success!
Running the script outputs the results just as I wanted them and, graphed in Excel, looks like this:
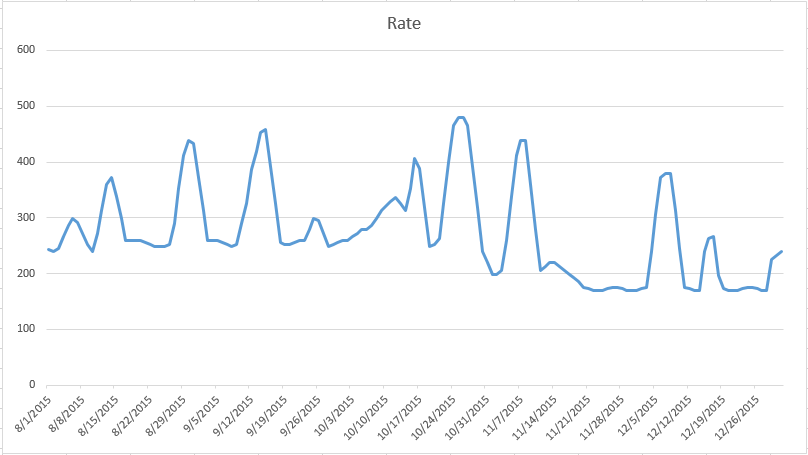
Awesome. In just a few lines of Python, I was able to get data allowing me to plan a vacation while saving quite a bit of cash.